Understanding Graph Database & Social Networks
Posted on February 28th, 2019
My team was working on implementing a knowledge graph with the help of the new SQL Server 2017’s Graph Database feature when I came to a realization that the world that we exist in is nothing but one giant knowledge graph.
Knowledge graph is the terminology used to describe the approach Google, LinkedIn, Facebook, Wikipedia, etc use to represent their data. This approach helps in enhancing their search results and process search queries faster and more accurately.
When talking about knowledge graph, every object that represents a unit of knowledge is a node. And each node might be connected to few other nodes with the help of edges. Edges represent a relationship between two nodes.
For example, let’s think about our real world. I have a friend, let’s call her Mia Khalifa - our relationship can be represented on a knowledge graph as shown below.
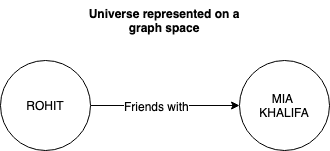
Now let’s assume for the sake of illustration, that the white space shown above is the entire universe represented in a knowledge graph space. In that universe, there’s me and my friend, Mia.
Let’s refer to me and Mia as nodes and the fact that we are friends means that we are connected to each other through an edge which is labelled as ‘friends with’ - Rohit - ‘friends with’ -> Mia Khalifa.
Now if we weren’t friends, there would not be any edge between us and we would exist in the universe as two entirely separate entities.
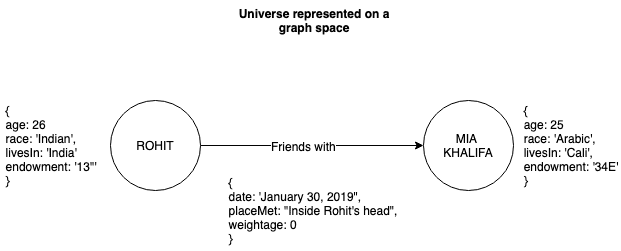
Collectively, me and Mia are both objects of the same type - humans (which is why we’re both represented as circles). Individually we may have different qualities which can be represented by our attributes and, objectively, it has nothing to do with the edge that connects us. Our friendship has nothing to do with the fact that Mia Khalifa is an accomplished and gifted adult filmstar - that would be ridiculous.
Similarly the edge between both the nodes can also have attributes that describe what the relationship is like between both the nodes. For example, the ‘friends with’ edge can have properties such as ‘date’ to describe the date on which we became friends, place where we met, or ‘weightage’ to describe the strength of our relationship (how good friends we are).
Now if I was to develop a social network using the graph structure described above - I could modify the weightage of our friendship based on every interaction we do with each other. For instance -
- If Mia likes my picture then weightage increases by 0.5 point
- If Mia messages me, the weightage increases by 1 point
- If Mia tags me in a picture with her, the weightage increases by 2 points
- If Mia sets her relationship status as ‘In a Relationship with Rohit,’ the weightage increases by 10000
Ok getting too ahead of myself there! But you get the idea.
The strength of the edge (defined by weightage) shows how strong the relationship between 2 nodes are. This way I can make sure that since Mia and my relationship is quite strong then I would probably not miss a single post by her.
This explains why there are always a few certain people we always see on top of our feed while there are rest we don’t ever see, no matter how active they might be.
About the author

Based in India. Building a few helpful things. Find me here talking about anything and everything. Keeping a track of my ideas so they don't get lost in the void. Tweet at me if you need me.